Exploring and Exploiting Stability in Latent Flow Matching
Published in ICML 2026
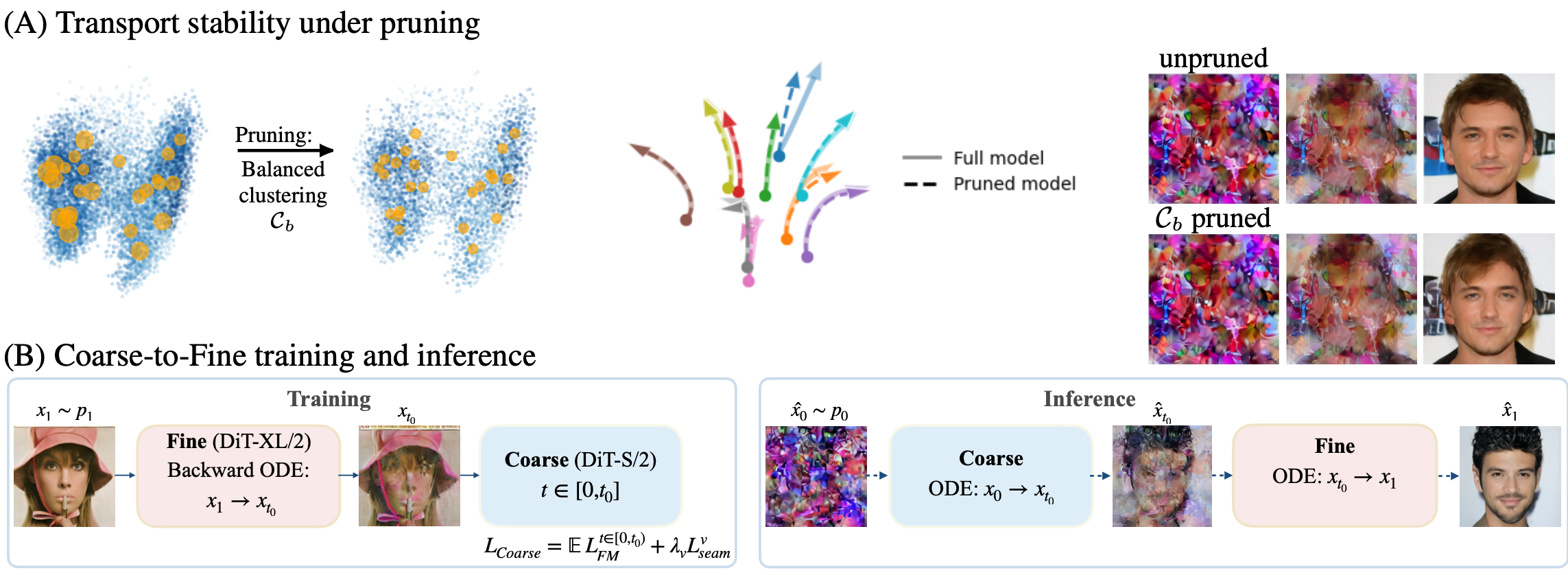
In this work, we show that Latent Flow-Matching (LFM) models are robust to different types of perturbations, including data reduction and model capacity shrinkage. We characterize this stability by their tendency to generate similar outputs under identical noise seeds. We provide a perspective relating this phenomenon to flow matching theory, which indicates that this stability is inherent to the FM objective. We further exploit this stability to derive practical algorithms for more efficient training and inference. Concretely, first, we show that by training LFM models on significantly reduced datasets, the performance does not degrade perceptually or quantitatively. This yields multiple advantages, such as reducing training time by converging faster under limited compute budget, and alleviating annotation effort when training conditional models. Second, LFM stability under architectural shrinkage gives rise to a two-model coarse-to-fine approach, one using a light-weight architecture for the first phase of the FM trajectory, and one with higher capacity for the second, thereby reducing the inference cost substantially. To determine which samples are informative, we introduce three sample-scoring criteria and evaluate them under standard metrics for generative models. Our results are thoroughly evaluated on multiple datasets, demonstrating the practical advantage of this stability, including data saving and a more than two-fold inference speedup while generating comparable outputs.
Authors: R. Briq, M. Kamp, O. Fried, S. Cohen, S. Kesselheim